
Predicting Portland Home Prices
For my final project at Metis, I wanted to choose something that enabled me to incorporate all that I had learned during the past three months. Predicting Portland home prices allowed me to do this because I was able to incorporate various web scraping techniques, natural language processing on text, deep learning models on images, and gradient boosting into tackling the problem.
Below you can see 8,300 single family home sales that I scraped in Portland, OR between July 2016 - July 2017.
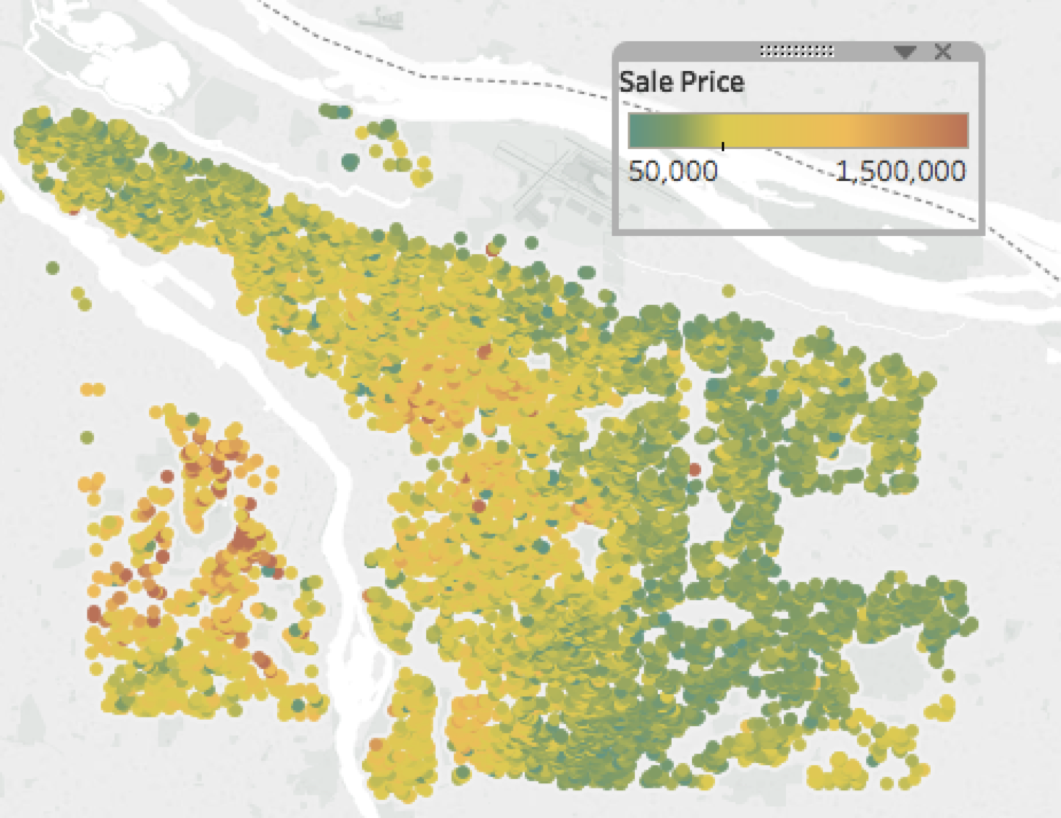
Obviously, neighborhood plays a large role. The West Hills (in red) are one of the priciest areas in town, whereas East Portland is cheaper. The average sale price was $442 K.
I wanted to be able to predict prices on a more granular level than neighborhood. For example, suppose the following houses were right next to each other.


These houses have the same square footage, were built the same year, are located on the exact same street. But, one has curb appeal and one clearly does not. How would Zillow or Redfin or anyone else trying to predict home prices know this from the home’s written specs alone? They wouldn’t. That’s why one of of the features that I wanted to incorporate into my model was an analysis of the front image of the home.
First things first, I needed to get all of the data. This proved to be more daunting than expected. First, I used the government API Portland Maps to scrape single family home sales in Portland. Unfortunately, the API had very small limits (about 150 calls per 10 minutes), so I had to leave the program running on an AWS server for quite a while to get all of the details. From there, I used the Zillow API to obtain the metadata and realtor description of each home, adhering to its API call limits.
Lastly, the most difficult part of the data gathering process was obtaining the images. This was because Zillow has an API but Redfin doesn’t, whereas Redfin leaves the images up after a house has sold whereas Zillow doesn’t. In order to get the Redfin images, I set up a Selenium script to search the home’s address on Google Images with the word “Redfin” at the end of the search entry, and then grabbed the first image URL that Google listed. In the end, I was able to obtain 8,300 homes with 8,300 corresponding images!
Once I had the data, I was ready to implement my model, depicted below:
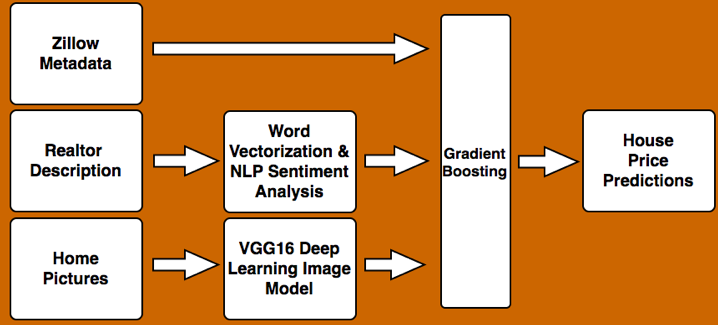
Let’s talk a little bit about each of the three input data types in detail. The Zillow metadata contained the descriptors you would expect - square footage, neighborhood, year built, etc. There were a few fun surprises when I sorted each feature by p-value. I definitely did not know what Georgian architecture was until I looked it up!

From there, I was ready to explore the realtor description using natural processing techniques. I did two things with the realtor description - I created a word vector matrix for each description that I could merge into a feature matrix with the Zillow metadata, and I used the NLTK sentiment package to calculate sentiment scores:

I suppose it was no surprise that the average positivity score for realtors was high (an average of 0.6 on a scale of -1 to +1). Therefore, adding sentiment score as a feature did not improve my model. However, it was fun exploring the most positive and negative scores in my data set:

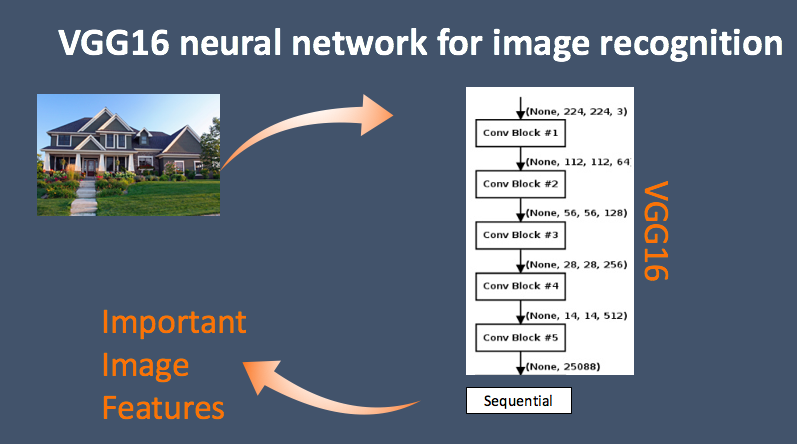
Finally, to incorporate the images into my model, I ran them through the VGG16 deep neural network for images in order to extract their features (which in turn became a 8300 x 25000 picture feature matrix). Running the model was pretty computationally intensive so I needed to install a g2.8xlarge GPU ubuntu instance on AWS.
How did the image model do in predicting home prices? Well! These were three of the highest-valued predicted homes in my test set, and clearly they were really nice homes:

Similarly, my image model did a good job at predicting inexpensive homes:

What types of images did my model have a hard time with? Ones with greenery! My model predicted that the lot below went for 2.5 million, when in fact, the city gave away that lot for free!

Okay, now that I was confident that my image model was doing a good job, I was ready to combine the Zillow metadata, realtor description word matrix, and the image feature matrix into one matrix and then implement gradient boosting in order to predict home prices. As a baseline prediction, recall that the average home price in my set was $442 K. If I predicted every home to be worth that much, then on average, I would be off by $161 K per house. Incorporating the images into my model immediately dropped that error by $20 K. Adding in the realtor description to that dropped it by another $10 K. Finally, adding in the Zillow metadata lowered the mean absolute error to approximately $71 K.
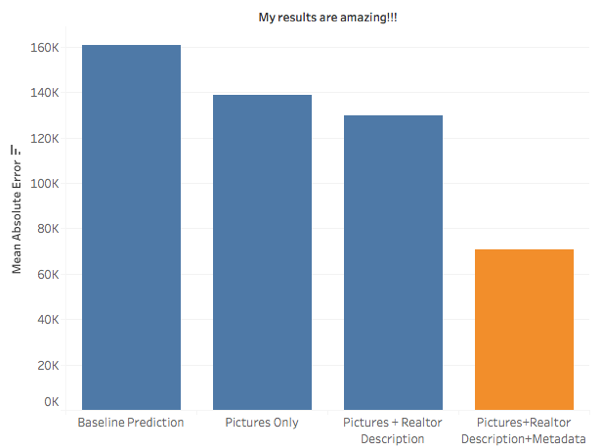
Not so fast, though. Perhaps you are wondering how well the Zillow metadata alone would do in predicting home prices? On average, it gives a $70 K error. Adding in realtor description drops that slightly to $69 K, but then adding in the pictures increases it to $71 K. In other words, the pictures right now are slightly hurting my model instead of helping it.
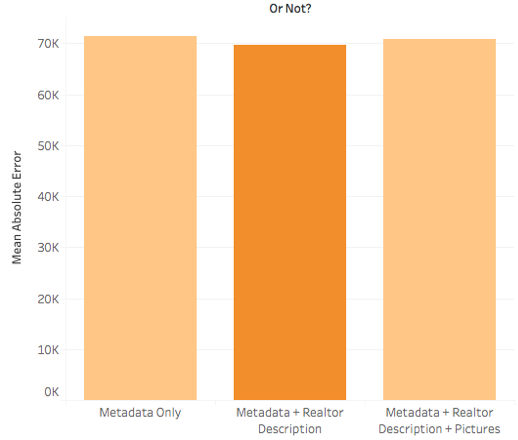
However, keep in mind that I am only using 8,300 photos, when the image feature matrix has 25,000 columns. I simply don’t have enough data yet to support this model. If I scraped the web for another month to get a lot more pictures, I am confident that incorporating the pictures into the model would help instead of hurt the prediction.
In summary, I learned a ton doing this project and overcame several significant hurdles. The biggest hurdles I encountered were figuring out how to scrape Redfin images and how to work with the VGG16 model. I found the Keras documentation to still be pretty minimal and so it was a lot of trial and error in getting it working. I’m really proud of myself for getting it to work - now I just need to get more data! You can find my GitHub repo for the project here.