
Gossip Article Recommendations And Celebrity Twitter Sentiment Analysis
I admit it, it’s a major character flaw of mine, but I love celebrity gossip. TMZ, US Weekly, you name it, I gotta have it. So, for our Natural Language Processing unit, I wanted to explore all things celebrity gossip.
My first objective was to find the hottest celebrity gossip topics of the summer. To do this, I scraped TMZ for all 1,507 articles published between June 9th and August 9th, 2017. I first tried using Selenium to grab the articles, but after a whole night of scraping and only 500 articles downloaded (due to the crazy slow loading of TMZ pages with all of their advertisements and photos) I realized that curling all of the articles was the way to go. It took less than a minute! From there, I used BeautifulSoup to collect the relevant text.
To pull out the most popular topics, I made a sci-kit learn pipeline that implemented TFIDF vectorization (and automatically removed stop words and discarded numbers and punctuation, too), a Truncated SVD for dimensionality reduction, and normalization. The ten most prominent topics are below.

As you can see above, the first topic is rather nonsensical. I would have guessed that “says”, “got”, “told”, and “just” were stop words that would have been removed by the sci-kit learn package, but apparently not. However, the next several topics are spot on. The scandalous Rob Kardashian - Blac Chyna breakup over her affair with Ferrari and the subsequent pics that got leaked were a hot topic. In addition, the Corrine-Demario Bachelor in Paradise pool scandal was big news. Of course, Justin Bieber canceling his tour because he found his purpose at church was another big headline. Notice that Chester appeared in three different topics. It makes sense that the suicide of Chester Bennington would appear in Topic 7 related his band, Linkin Park, and the suicide of his friend, Chris Cornell, but it was a bit puzzling that his name appeared in three different topics.
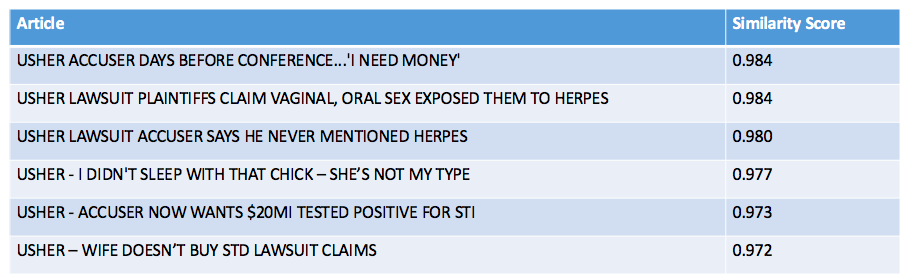
Okay. My second objective was to find articles similar to an article of interest in order to suggest recommendations to TMZ readers. To do this, I implemented Gensim’s similarity matrix that measured cosine distance between vectors. Using this algorithm, I found that if you really liked this article on Usher’s herpes scandal, for example, then you would most like these other articles:
My third objective was to use unsupervised learning techniques to cluster articles. The algorithm DBSCAN chooses how many clusters to use. It chose 13, and so I also used 13 K-Means clusters for comparison. Hands down, K-Means was the superior clustering algorithm for this data set. You can see clear structure in the second picture:
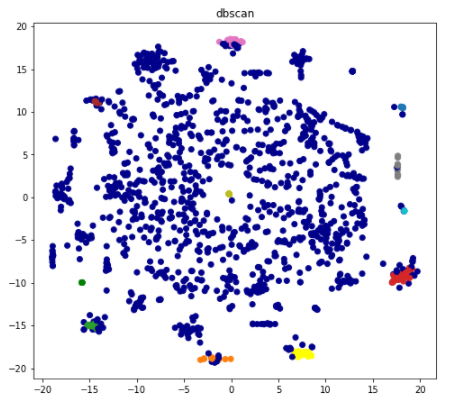
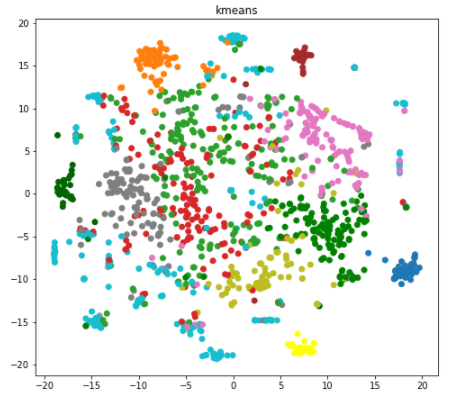
My fourth objective was to visualize how close some of the hottest summer topics were to each other using a two dimensional t-SNE plot. Remember, I had 1,507 documents and after removing stopwords and words that appeared less than 10 times, I had a 1,507 x 1,640 doc-word matrix. Thus, the fact that the t-SNE algorithm allows dimensionality reduction that preserves distance but allows me to visualize things in a simple 2D plane is super cool! Below, you can use the D3 visualization to view the proximity of articles containing the following hot topics:
Some characteristics of the t-SNE plot made intuitive sense. The blue Bachelor and black Usher points were near each other, probably as they both related to sex scandals. Similarly, the yellow O.J. Simpson and cyan Bill Cosby points were nearby, as they dealt with legal trials. However, I was surprised that the pink Rob Kardashian points weren’t closer to the Kim Kardashian grey points, as they are relatives.
You might be wondering which celebrity names appeared most frequently in TMZ articles in the summer of 2017. Well, you could visualize the frequency using a fancy D3 word cloud:
Or, you could view it (my preferred) old-fashioned way, in a list:

My last objective was to use scikit-learn’s NLTK Vader library to do some sentiment analysis on the most popular celebrity twitter accounts. Out of all of the celebs listed, who was the most positive? Neil Patrick Harris, with an average sentiment score of 0.4254.

His tweets are hilarious - they are all SOOOOOO upbeat that you kind of want to smack him:

Who were the most negative celebrities? Chris Brown and Snoop Dogg. Chris Brown didn’t surprise me, but Snoop Dogg sure did. He seems like a fun fellow. Why did he only have an average sentiment score of 0.06?

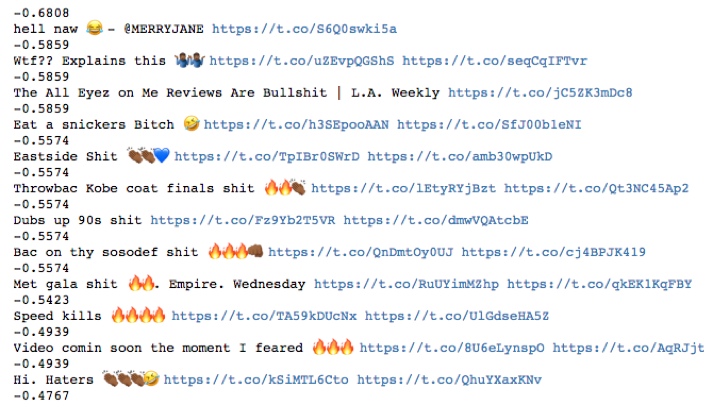
Well, upon closer examination, the sentiment analyzer really doesn’t pick up on his language subtleties. “This is the shit” is considered a bad thing:
In summary, I had a blast doing this project. While the topic of celebrity gossip was rather silly, it was broad enough to allow me to investigate many different areas of Natural Language Processing, and in a context in which I already had intitution for what the results of the model should give me. You can find my GitHub repo for the project here.